
تحلیل داده با پایتون
تحلیل داده با پایتون تکنیکی برای جمعآوری، تبدیل و سازماندهی دادهها به منظور انجام پیشبینیهای آینده و تصمیمگیریهای مبتنی بر داده است. همچنین، این روش به یافتن راهحلهای ممکن برای مشکلات کسبوکار کمک میکند.
مواردی که در مقاله به آن پرداخته میشود:
- تحلیل دادههای عددی با NumPy
- عملیات روی آرایههای NumPy
- دسترسی به ایندکس در آرایههای NumPy
- تحلیل داده با استفاده از پانداز (Pandas)
- ادغام DataFrame ها
- مصورسازی با Matplotlib
- تحلیل اکتشافی دادهها (EDA)

تحلیل داده های عددی با NumPy
NumPy یک بستهی پردازش آرایه در پایتون است و یک شیء آرایه چندبعدی با کارایی بالا و ابزارهایی برای کار با این آرایهها ارائه میدهد. این بسته اصلی برای محاسبات علمی با پایتون محسوب میشود.
آرایهها در NumPy
آرایه NumPy جدولی از عناصر (معمولاً اعداد) با انواع مشابه است که با یک تاپل از اعداد صحیح مثبت ایندکس شدهاند. در NumPy، تعداد ابعاد آرایه به عنوان “رتبه آرایه” شناخته میشود. یک تاپل از اعداد صحیح که اندازه آرایه در هر بعد را مشخص میکند به عنوان “شکل آرایه” شناخته میشود.
ایجاد آرایههای NumPy
آرایههای NumPy میتوانند به روشهای مختلفی برای تحلیل داده با رتبههای مختلف ایجاد شوند. آنها همچنین میتوانند با استفاده از انواع مختلفی از دادهها مانند لیستها، تاپلها و غیره ایجاد شوند. نوع آرایهای که ایجاد میشود از نوع عناصر در دنبالهها استنباط میشود. NumPy چندین تابع برای ایجاد آرایهها با محتوای اولیه فراهم میکند که نیاز به رشد آرایهها را به حداقل میرساند، که عملیاتی پرهزینه است.
ایجاد آرایه با استفاده از numpy.empty
import numpy as np
b = np.empty(2, dtype = int)
print(“Matrix b : \n”, b)
a = np.empty([2, 2], dtype = int)
print(“\nMatrix a : \n”, a)
c = np.empty([3, 3])
print(“\nMatrix c : \n”, c)
خروجی:

ایجاد آرایه با استفاده از numpy.zeros
در این بخش، نحوه ایجاد آرایههای NumPy با مقادیر اولیه صفر با استفاده از تابع numpy.zeros را توضیح خواهیم داد.
import numpy as np
b = np.zeros(2, dtype = int)
print(“Matrix b : \n”, b)
a = np.zeros([2, 2], dtype = int)
print(“\nMatrix a : \n”, a)
c = np.zeros([3, 3])
print(“\nMatrix c : \n”, c)
خروجی:
Matrix b :
[0 0]
Matrix a :
[[0 0]
[0 0]]
Matrix c :
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
توضیحات کد:
ایمپورت کتابخانه NumPy:
import numpy as np
ابتدا کتابخانه NumPy را با نام مستعار np ایمپورت میکنیم تا از توابع آن استفاده کنیم.
ایجاد آرایه تک بعدی:
b = np.zeros(2, dtype = int)
print(“Matrix b : \n”, b)
در این قسمت، آرایهای تک بعدی با طول ۲ و نوع دادهای int ایجاد میشود که تمامی مقادیر آن صفر است.
ایجاد آرایه دو بعدی:
a = np.zeros([2, 2], dtype = int)
print(“\nMatrix a : \n”, a)
در این بخش، آرایهای دوبعدی با ابعاد ۲×۲ و نوع دادهای int ایجاد میشود که تمامی مقادیر آن صفر است.
ایجاد آرایه سه بعدی:
a = np.zeros([2, 2], dtype = int)
print(“\nMatrix a : \n”, a)
در این قسمت، آرایهای سهبعدی با ابعاد ۳×۳ و نوع دادهای پیشفرض float ایجاد میشود که تمامی مقادیر آن صفر است.
این روش به ما امکان میدهد تا به سرعت آرایههایی با مقادیر اولیه صفر ایجاد کنیم که میتوانند برای محاسبات و تحلیل داده های علمی بسیار مفید باشند.
عملیات روی آرایههای NumPy
عملیات حسابی
در NumPy، میتوانیم عملیاتهای حسابی مختلفی را بر روی آرایهها انجام دهیم، از جمله جمع، تفریق، ضرب و تقسیم.
جمع:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing addition using arithmetic operator
add_ans = a+b
print(add_ans)
# Performing addition using numpy function
add_ans = np.add(a, b)
print(add_ans)
# The same functions and operations can be used for
# multiple matrices
c = np.array([1, 2, 3, 4])
add_ans = a+b+c
print(add_ans)
add_ans = np.add(a, b, c)
print(add_ans)
خروجی:
[ 7 77 23 130]
[ 7 77 23 130]
[ 8 79 26 134]
[ 7 77 23 130]
تفریق:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing subtraction using arithmetic operator
sub_ans = a-b
print(sub_ans)
# Performing subtraction using numpy function
sub_ans = np.subtract(a, b)
print(sub_ans)
خروجی:
[ 3 67 3 70]
[ 3 67 3 70]
ضرب:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing multiplication using arithmetic
# operator
mul_ans = a*b
print(mul_ans)
# Performing multiplication using numpy function
mul_ans = np.multiply(a, b)
print(mul_ans)
خروجی:
[ 10 360 130 3000]
[ 10 360 130 3000]
تقسیم:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing division using arithmetic operators
div_ans = a/b
print(div_ans)
# Performing division using numpy functions
div_ans = np.divide(a, b)
print(div_ans)
خروجی:
[ 2.5 14.4 1.3 3.33333333]
[ 2.5 14.4 1.3 3.33333333]
این عملیاتها نشان میدهند که NumPy به راحتی قادر است تا عملیات حسابی پیچیدهتر را بر روی آرایههای چندبعدی انجام دهد، که بسیار مفید برای محاسبات علمی و عملیات دادهپردازی است.
دسترسی به ایندکس های آرایههای NumPy
در NumPy، میتوانیم با استفاده از یک آرایه دیگر به عنوان اندیس، دسترسی به اعضای مختلف یک آرایه را داشته باشیم. در صورت استفاده از اسلایس (slice)، یک نمای یا کپی سطحی از آرایه برگردانده میشود، اما در صورت استفاده از آرایه اندیس، یک کپی از آرایه اصلی برگردانده میشود. آرایههای NumPy میتوانند با آرایههای دیگر یا هر دنبالهای با استثنای تاپلها، اندیسگذاری شوند. اندیس آخر با -1، دومین اندیس با -2 و به همین ترتیب اندیسها مشخص میشوند.
دسترسی به اندیسهای آرایههای NumPy
# Python program to demonstrate
# the use of index arrays.
import numpy as np
# Create a sequence of integers from
# 10 to 1 with a step of -2
a = np.arange(10, 1, -2)
print(“\n A sequential array with a negative step: \n”,a)
# Indexes are specified inside the np.array method.
newarr = a[np.array([3, 1, 2 ])]
print(“\n Elements at these indices are:\n”,newarr)
خروجی:
A sequential array with a negative step:
[10 8 6 4 2]
Elements at these indices are:
[4 8 6]
برشگیری از آرایههای NumPy
در NumPy، عبارت x[obj] را میتوان بهعنوان اندیسگذاری در نظر گرفت، جایی که x آرایه و obj اندیس است. در مورد برشگیری اساسی، obj:
یک شیء برش است که به صورت start:stop
تعریف شده است.
یک عدد صحیح است.
یا یک تاپل از شیءهای برش و عدد صحیحها است.
همه آرایههای تولید شده توسط برشگیری اساسی همواره نمای (view) از آرایه اصلی هستند.
برشگیری از آرایههای NumPy
# Python program for basic slicing.
import numpy as np
# Arrange elements from 0 to 19
a = np.arange(20)
print(“\n Array is:\n “,a)
# a[start:stop:step]
print(“\n a[-8:17:1] = “,a[-8:17:1])
# The : operator means all elements till the end.
print(“\n a[10:] = “,a[10:])
خروجی:
Array is:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
a[-8:17:1] = [12 13 14 15 16]
a[10:] = [10 11 12 13 14 15 16 17 18 19]
همچنین میتوان از Ellipsis (…) در کنار برشگیری اساسی استفاده کرد. Ellipsis (…) تعدادی عملگر : لازم برای ایجاد یک تاپل انتخابی به همان طول ابعاد آرایه را نشان میدهد.
برشگیری از آرایههای NumPy با استفاده از Ellipsis
# Python program for indexing using basic slicing with ellipsis
import numpy as np
# A 3 dimensional array.
b = np.array([[[1, 2, 3],[4, 5, 6]],
[[7, 8, 9],[10, 11, 12]]])
print(b[…,1]) #Equivalent to b[: ,: ,1 ]
خروجی:
[[ 2 5]
[ 8 11]]
این مثالها نشان میدهند که NumPy به راحتی قادر است با استفاده از اندیسگذاری و برشگیری، عملیاتهای پیچیده را بر روی آرایههای چندبعدی انجام دهد، که بسیار مفید برای تحلیل داده و پردازش علمی است.
پخش (Broadcasting) آرایههای NumPy
مفهوم پخش به این اشاره دارد که چگونه NumPy با آرایههایی که ابعاد مختلفی دارند هنگام عملیات حسابی رفتار میکند، که به محدودیتهای خاصی منجر میشود. آرایه کوچکتر به سراسر آرایه بزرگتر پخش میشود تا ابعادشان سازگار باشند.
بیایید فرض کنیم که یک مجموعه داده بزرگ داریم، هر داده یک لیستی از پارامترها است. در NumPy، یک آرایه دوبعدی داریم که هر ردیف یک داده است و تعداد ردیفها اندازه مجموعه داده است. فرض کنید میخواهیم یک نوع اسکیلینگ را بر روی همه این دادهها اعمال کنیم، بهطوری که هر پارامتر به یک عامل مقیاس داده خودش ضرب شود یا به عبارت دیگر هر پارامتر در عاملی مقیاسی ضرب شود.

برای مثال، اگر بخواهیم در این تحلیل داده کالری موجود در مواد غذایی را بر اساس ترکیبات ماکرونوتریانت محاسبه کنیم، میتوانیم از ترکیبات چربیها (9 کالری بر گرم)، پروتئینها (4 کالری بر گرم) و کربوهیدراتها (4 کالری بر گرم) استفاده کنیم. لذا اگر مواد غذایی مختلفی را لیست کنیم (دادههای ما)، و برای هر ماده غذایی ترکیب ماکرونوتریانت آن را لیست کنیم (پارامترها)، میتوانیم هر ماده را با مقدار کالریاش ضرب کنیم (اعمال اسکیلینگ) تا تجزیه کالریهر ماده غذایی را محاسبه کنیم.
پخش آرایههای NumPy
برای این تبدیل، میتوانیم اطلاعات مفید مختلفی را محاسبه کنیم. به عنوان مثال، مجموع کل کالریهای موجود در برخی مواد غذایی یا، با توجه به ترکیبات شامم، چند کالری پروتئین گرفتهام را بدانم و غیره.
حالا بیایید یک روش ساده برای تولید این محاسبه را با استفاده از NumPy ببینیم:
import numpy as np
macros = np.array([
[0.8, 2.9, 3.9],
[52.4, 23.6, 36.5],
[55.2, 31.7, 23.9],
[14.4, 11, 4.9]
])
# Create a new array filled with zeros,
# of the same shape as macros.
result = np.zeros_like(macros)
cal_per_macro = np.array([3, 3, 8])
# Now multiply each row of macros by
# cal_per_macro. In Numpy, `*` is
# element-wise multiplication between two arrays.
for i in range(macros.shape[0]):
result[i, :] = macros[i, :] * cal_per_macro
result
خروجی:
array([[ 7.2, 11.6, 15.6],
[471.6, 94.4, 146. ],
[496.8, 126.8, 95.6],
[129.6, 44. , 19.6]])
قوانین پخش (Broadcasting)
پخش دو آرایه با همدیگر این قوانین را دنبال میکند:
- اگر آرایهها رتبه یکسان نداشته باشند، شکل آرایه با رتبه پایینتر را با ۱ها پیشوند میدهد تا هر دو شکل یکسان شوند.
- دو آرایه در یک بعد سازگار هستند اگر اندازه یکسانی در آن بعد داشته باشند یا اگر یکی از آرایهها اندازه ۱ در آن بعد داشته باشد.
- آرایهها میتوانند با هم پخش شوند اگر در تمام ابعاد سازگار باشند.
- پس از پخش، هر آرایه به صورتی عمل میکند که اندازه آن برابر با حداکثر اندازه آرایههای ورودی است.
- در هر بعد که یکی از آرایهها اندازه ۱ داشته باشد و دیگری اندازه بیشتر از ۱ داشته باشد، آرایه اولی به عنوان اینکه در آن بعد کپی شده است، رفتار میکند.
این مثالها نشان میدهند که NumPy به راحتی قادر است با استفاده از پخش، عملیاتهای پیچیده را بر روی آرایههای مختلف انجام دهد که بسیار مفید برای تحلیل دادهها و محاسبات علمی است.
import numpy as np
v = np.array([12, 24, 36])
w = np.array([45, 55])
# To compute an outer product we first
# reshape v to a column vector of shape 3×1
# then broadcast it against w to yield an output
# of shape 3×2 which is the outer product of v and w
print(np.reshape(v, (3, 1)) * w)
X = np.array([[12, 22, 33], [45, 55, 66]])
# x has shape 2×3 and v has shape (3, )
# so they broadcast to 2×3,
print(X + v)
# Add a vector to each column of a matrix X has
# shape 2×3 and w has shape (2, ) If we transpose X
# then it has shape 3×2 and can be broadcast against w
# to yield a result of shape 3×2.
# Transposing this yields the final result
# of shape 2×3 which is the matrix.
print((X.T + w).T)
# Another solution is to reshape w to be a column
# vector of shape 2X1 we can then broadcast it
# directly against X to produce the same output.
print(X + np.reshape(w, (2, 1)))
# Multiply a matrix by a constant, X has shape 2×3.
# Numpy treats scalars as arrays of shape();
# these can be broadcast together to shape 2×3.
print(X * 2)
خروجی:
[[ 540 660]
[1080 1320]
[1620 1980]]
[[ 24 46 69]
[ 57 79 102]]
[[ 57 67 78]
[100 110 121]]
[[ 57 67 78]
[100 110 121]]
[[ 24 44 66]
[ 90 110 132]]
کد نشان می دهد که چگونه برگشت و شیوه پخش در NumPy استفاده می شود، که امکان عملیات بین ماتریسهایی با ابعاد مختلف را فراهم می کند.
- پخش امکان محاسبات کارآمد را ایجاد می کند با حذف نیاز به حلقه های صریح بر روی عناصر ماتریسها.
- درک قوانین پخش در NumPy برای کار بهینه با ماتریسها و آرایه های چند بعدی بسیار حیاتی است.
تحلیل داده با استفاده از پانداز (Pandas)
در تحلیل داده با پانداز در پایتون برای دادههای رابطهای یا دادههای برچسبخورده استفاده میشود و ساختارهای دادهای مختلفی را برای انعطاف پذیری در کار با این دادهها و سری زمانی فراهم میکند. این کتابخانه بر روی کتابخانه NumPy ساخته شده است. این ماژول معمولاً به شکل زیر وارد میشود:
import pandas as pd
در اینجا، pd به عنوان نام مستعاری به Pandas اشاره دارد. با این حال، لازم نیست که کتابخانه را با نام مستعار وارد کنید، اما این کمک میکند که هر بار که یک متد یا ویژگی فراخوانی میشود، کد کمتری بنویسید. پانداز به طور کلی دو ساختار داده برای کار با دادهها فراهم میکند:
سری (Series)
سری پانداز یک آرایه یک بعدی با برچسب است که قابلیت نگهداری دادههای هر نوعی را دارد (عدد صحیح، رشته، عدد ممیز شناور، اشیاء پایتون و غیره). برچسبهای محور به طور مجموع به شاخصها گفته میشوند. سری پانداز هیچوقت نیازی به برچسبهای یکتا ندارد اما باید نوعی قابل هش کننده باشند. این شیء هم اندیسبندی مبتنی بر عدد و هم مبتنی بر برچسب را پشتیبانی میکند و ارائهدهنده انواعی از متدها برای انجام عملیات شامل اندیس میباشد.

میتوان آن را با استفاده از تابع () Series و با بارگذاری مجموعه داده از ذخیره سازی موجود مانند SQL، پایگاه داده، فایلهای CSV، فایلهای اکسل و غیره ایجاد کرد.
ایجاد سری پانداز در پایتون
import pandas as pd
import numpy as np
# Creating empty series
ser = pd.Series()
print(ser)
# simple array
data = np.array([‘g’, ‘e’, ‘e’, ‘k’, ‘s’])
ser = pd.Series(data)
print(ser)
خروجی:
Series([], dtype: float64)
0 g
1 e
2 e
3 k
4 s
dtype: object
فریم داده (DataFrame)
دیتافریم پانداز یک ساختار داده دوبعدی با اندازه قابل تغییر است که در اصل یک جدول دادهای میباشد که دادهها، ردیفها و ستونها با برچسب دارد. فریم داده پانداز از سه مؤلفه اصلی تشکیل شده است: داده، ردیفها و ستونها.

فریم داده میتواند با استفاده از متد DataFrame() ایجاد شود و همانند سری، میتواند از انواع مختلفی از فایلها و ساختارهای دادهای ایجاد شود.
ایجاد فریم داده پانداز در پایتون
import pandas as pd
# Calling DataFrame constructor
df = pd.DataFrame()
print(df)
# list of strings
lst = [‘Geeks’, ‘For’, ‘Geeks’, ‘is’,
‘portal’, ‘for’, ‘Geeks’]
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
df
خروجی:
Empty DataFrame
Columns: []
Index: []
0
0 Geeks
1 For
2 Geeks
3 is
4 portal
5 for
6 Geeks
ایجاد فریم داده از CSV
میتوانیم یک فریم داده را از فایلهای CSV با استفاده از تابع () read_csv ایجاد کنیم.
خواندن فایل CSV در پانداز
import pandas as pd
# Reading the CSV file
df = pd.read_csv(“Iris.csv”)
# Printing top 5 rows
df.head()
خروجی:
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa

این مثالها نشان میدهند که پانداز چگونه به راحتی میتواند دادههای مختلف را در ساختارهای دادهای مختلفی مانند سری و فریم داده نمایش دهد، که بسیار کاربردی برای تحلیل داده ها و پردازش آنهاست.
فیلتر کردن دادهها در DataFrame
تابع ()dataframe.filter در Pandas برای زیرمجموعهسازی ردیفها یا ستونهای یک DataFrame بر اساس برچسبها در اندیس مشخص شده استفاده میشود. توجه کنید که این روش فقط بر اساس برچسبهای اندیس دادهها را فیلتر میکند و به محتوای واقعی دادهها توجه نمیکند.
فیلتر کردن DataFrame در پانداز
import pandas as pd
# Reading the CSV file
df = pd.read_csv(“Iris.csv”)
# applying filter function
df.filter([“Species”, “SepalLengthCm”, “SepalLengthCm”]).head()
خروجی:
Species SepalLengthCm
0 setosa 5.1
1 setosa 4.9
2 setosa 4.7
3 setosa 4.6
4 setosa 5.0

مرتبسازی DataFrame
برای مرتبسازی DataFrame در پانداز از تابع () sort_values استفاده میشود که میتواند دادهها را به صورت صعودی یا نزولی مرتب کند.
import pandas as pd
# خواندن فایل CSV
df = pd.read_csv(“Iris.csv”)
# اعمال تابع filter()
df.filter([“Species”, “SepalLengthCm”]).head()
خروجی:
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
13 4.3 3.0 1.1 0.1 setosa
42 4.4 3.2 1.3 0.2 setosa
38 4.4 3.0 1.3 0.2 setosa
8 4.4 2.9 1.4 0.2 setosa
41 4.5 2.3 1.3 0.3 setosa

گروه بندی در Pandas
مفهوم GroupBy در pandas بسیار ساده است. ما میتوانیم دستهبندیهایی ایجاد کرده و یک تابع را به این دستهها اعمال کنیم. در پروژههای واقعی علم داده، شما با حجم زیادی از دادهها سر و کار دارید و ممکن است بخواهید به طور مکرر تحلیل داده مختلف را انجام دهید، بنابراین برای کارایی بیشتر، از مفهوم GroupBy استفاده میکنیم.
مفهوم GroupBy عمدتاً به فرآیندی اشاره دارد که شامل یک یا چند مرحله زیر است:
- تقسیم (Splitting): فرآیندی است که در آن دادهها را با اعمال برخی شرایط بر روی مجموعه دادهها به گروههای مختلف تقسیم میکنیم.
- اعمال (Applying): فرآیندی است که در آن یک تابع را به هر گروه به طور مستقل اعمال میکنیم.
- ترکیب (Combining): فرآیندی است که در آن پس از اعمال گروهبندی، دادههای مختلف را ترکیب کرده و به یک ساختار دادهای تبدیل میکنیم.
1. گروه بندی مقادیر منحصر به فرد از ستون تیم

2. اکنون برای هر گروه یک سطل (bucket) وجود دارد:

3. دادههای دیگر را به سطلها بریزید:
4. اعمال یک تابع بر روی ستون وزن هر سطل:

کد نمونه
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {‘Name’: [‘Jai’, ‘Anuj’, ‘Jai’, ‘Princi’,
‘Gaurav’, ‘Anuj’, ‘Princi’, ‘Abhi’],
‘Age’: [27, 24, 22, 32,
33, 36, 27, 32],
‘Address’: [‘Nagpur’, ‘Kanpur’, ‘Allahabad’, ‘Kannuaj’,
‘Jaunpur’, ‘Kanpur’, ‘Allahabad’, ‘Aligarh’],
‘Qualification’: [‘Msc’, ‘MA’, ‘MCA’, ‘Phd’,
‘B.Tech’, ‘B.com’, ‘Msc’, ‘MA’]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(“Original Dataframe”)
display(df)
# applying groupby() function to
# group the data on Name value.
gk = df.groupby(‘Name’)
# Let’s print the first entries
# in all the groups formed.
print(“After Creating Groups”)
gk.first()
خروجی :
DataFrame اصلی
Name Age Address Qualification
0 Jai 27 Nagpur Msc
1 Anuj 24 Kanpur MA
2 Jai 22 Allahabad MCA
3 Princi 32 Kannuaj Phd
4 Gaurav 33 Jaunpur B.Tech
5 Anuj 36 Kanpur B.com
6 Princi 27 Allahabad Msc
7 Abhi 32 Aligarh MA
پس از ایجاد گروهها
Age Address Qualification
Name
Abhi 32 Aligarh MA
Anuj 24 Kanpur MA
Gaurav 33 Jaunpur B.Tech
Jai 27 Nagpur Msc
Princi 32 Kannuaj Phd

این مثال نشان میدهد که چگونه میتوانیم دادهها را بر اساس یک ستون گروهبندی کنیم و سپس یک تابع را به هر گروه اعمال کنیم.
اعمال تابع به گروهها
پس از تقسیم دادهها به گروهها، ما یک تابع را به هر گروه اعمال میکنیم. برای انجام این کار، چند عملیات را انجام میدهیم که عبارتند از:
تجمیع (Aggregation)
این فرآیندی است که در آن ما یک آمار خلاصه (یا آمارها) را برای هر گروه محاسبه میکنیم. تابع تجمیع یک مقدار تجمیعی برای هر گروه برمیگرداند. پس از تقسیم دادهها به گروهها با استفاده از تابع groupby، میتوان چندین عملیات تجمیع را بر روی دادههای گروهبندی شده انجام داد.
تبدیل (Transformation)
این فرآیندی است که در آن ما محاسبات خاص هر گروه را انجام میدهیم و نتیجه را به صورت ایندکسبندی مشابه برمیگردانیم. به عنوان مثال، پر کردن مقادیر نال (NA) درون گروهها با مقداری که از هر گروه استخراج شده است.
فیلتراسیون (Filtration)
این فرآیندی است که در آن برخی گروهها را بر اساس یک محاسبه گروهی که به صورت True یا False ارزیابی میشود، حذف میکنیم. به عنوان مثال، فیلتر کردن دادهها بر اساس مجموع یا میانگین گروه.
تجمیع در Pandas
دراین بخش از تحلیل داده ، تجمیع فرآیندی است که در آن ما یک آمار خلاصه برای هر گروه محاسبه میکنیم. تابع تجمیع یک مقدار تجمیعی برای هر گروه برمیگرداند. پس از تقسیم دادهها به گروهها با استفاده از تابع groupby، میتوان چندین عملیات تجمیع را بر روی دادههای گروهبندی شده انجام داد.
مثال: تجمیع در Pandas
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {‘Name’: [‘Jai’, ‘Anuj’, ‘Jai’, ‘Princi’,
‘Gaurav’, ‘Anuj’, ‘Princi’, ‘Abhi’],
‘Age’: [27, 24, 22, 32,
33, 36, 27, 32],
‘Address’: [‘Nagpur’, ‘Kanpur’, ‘Allahabad’, ‘Kannuaj’,
‘Jaunpur’, ‘Kanpur’, ‘Allahabad’, ‘Aligarh’],
‘Qualification’: [‘Msc’, ‘MA’, ‘MCA’, ‘Phd’,
‘B.Tech’, ‘B.com’, ‘Msc’, ‘MA’]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
# performing aggregation using
# aggregate method
grp1 = df.groupby(‘Name’)
grp1.aggregate(np.sum)
خروجی :
Age Address Qualification
Name
Abhi 32 Aligarh MA
Anuj 60 Kanpur MAB.com
Gaurav 33 Jaunpur B.Tech
Jai 49 NagpurAllahabad MscMCA
Princi 59 KannuajAllahabad PhdMsc

این مثال نشان میدهد که چگونه میتوانیم دادهها را بر اساس یک ستون گروهبندی کنیم و سپس یک تابع تجمیع را به هر گروه اعمال کنیم. در اینجا از تابع np.sum برای محاسبه مجموع مقادیر در هر گروه استفاده شده است.
ترکیب DataFrame
برای ترکیب DataFrame در pandas از تابع ()concat استفاده میکنیم که به ما کمک میکند تا DataFrame را به هم متصل کنیم. این تابع تمامی عملیاتهای ترکیب را همراه با یک محور از اشیای pandas انجام میدهد و در صورت وجود، منطق اختیاری مجموعه (اتحاد یا اشتراک) ایندکسها را در محورهای دیگر اجرا میکند.
ترکیب DataFrame با pandas
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {‘key’: [‘K0’, ‘K1’, ‘K2’, ‘K3’],
‘Name’:[‘Jai’, ‘Princi’, ‘Gaurav’, ‘Anuj’],
‘Age’:[27, 24, 22, 32],}
# Define a dictionary containing employee data
data2 = {‘key’: [‘K0’, ‘K1’, ‘K2’, ‘K3’],
‘Address’:[‘Nagpur’, ‘Kanpur’, ‘Allahabad’, ‘Kannuaj’],
‘Qualification’:[‘Btech’, ‘B.A’, ‘Bcom’, ‘B.hons’]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
# Convert the dictionary into DataFrame
df1 = pd.DataFrame(data2)
display(df, df1)
# combining series and dataframe
res = pd.concat([df, df1], axis=1)
res
خروجی :
key Name Age
0 K0 Jai 27
1 K1 Princi 24
2 K2 Gaurav 22
3 K3 Anuj 32
key Address Qualification
0 K0 Nagpur Btech
1 K1 Kanpur B.A
2 K2 Allahabad Bcom
3 K3 Kannuaj B.hons
key Name Age key Address Qualification
0 K0 Jai 27 K0 Nagpur Btech
1 K1 Princi 24 K1 Kanpur B.A
2 K2 Gaurav 22 K2 Allahabad Bcom
3 K3 Anuj 32 K3 Kannuaj B.hons

در این مثال، دو دیکشنری شامل دادههای کارمندان تعریف شدهاند که هر کدام شامل یک کلید (key) و اطلاعات مختلفی در مورد کارمندان هستند. سپس این دیکشنریها به DataFrame تبدیل شدهاند و با استفاده از تابع ()concat این دو DataFrame به هم متصل شدهاند. نتیجه نهایی شامل تمامی ستونهای هر دو DataFrame است که به صورت ستونی (محور axis=1) ترکیب شدهاند.
ادغام DataFrame ها
هنگامی که نیاز به ترکیب DataFrameهای بسیار بزرگ برای تحلیل داده داریم، استفاده از joinها به عنوان روشی قدرتمند برای انجام سریع این عملیاتها خدمت میکند. Joinها تنها میتوانند بین دو DataFrame انجام شوند که به عنوان جداول چپ و راست مشخص میشوند. کلید، ستون مشترکی است که دو DataFrame بر اساس آن به هم ملحق میشوند. بهتر است از کلیدهایی استفاده کنید که در طول ستون مقادیر منحصر به فردی دارند تا از تکرار ناخواسته مقادیر ردیف جلوگیری شود. pandas یک تابع واحد به نام ()merge ارائه میدهد که به عنوان نقطه ورودی برای تمام عملیاتهای join استاندارد بین اشیای DataFrame عمل میکند.
چهار روش اصلی برای انجام join وجود دارد (داخلی، چپ، راست و بیرونی) که بر اساس اینکه کدام ردیفها باید دادههای خود را حفظ کنند، انتخاب میشوند.
ترکیب DataFrame با pandas
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {‘key’: [‘K0’, ‘K1’, ‘K2’, ‘K3’],
‘Name’:[‘Jai’, ‘Princi’, ‘Gaurav’, ‘Anuj’],
‘Age’:[27, 24, 22, 32],}
# Define a dictionary containing employee data
data2 = {‘key’: [‘K0’, ‘K1’, ‘K2’, ‘K3’],
‘Address’:[‘Nagpur’, ‘Kanpur’, ‘Allahabad’, ‘Kannuaj’],
‘Qualification’:[‘Btech’, ‘B.A’, ‘Bcom’, ‘B.hons’]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
# Convert the dictionary into DataFrame
df1 = pd.DataFrame(data2)
display(df, df1)
# using .merge() function
res = pd.merge(df, df1, on=’key’)
res
خروجی :
key Name Age
0 K0 Jai 27
1 K1 Princi 24
2 K2 Gaurav 22
3 K3 Anuj 32
key Address Qualification
0 K0 Nagpur Btech
1 K1 Kanpur B.A
2 K2 Allahabad Bcom
3 K3 Kannuaj B.hons
key Name Age Address Qualification
0 K0 Jai 27 Nagpur Btech
1 K1 Princi 24 Kanpur B.A
2 K2 Gaurav 22 Allahabad Bcom
3 K3 Anuj 32 Kannuaj B.hons

ادغام DataFrame ها
برای ادغام DataFrame ها، از تابع ()join استفاده میکنیم. این تابع برای ترکیب ستونهای دو DataFrame که ممکن است به طور متفاوتی ایندکس شده باشند به یک DataFrame نتیجهی واحد به کار میرود.
ادغام DataFrame ها با استفاده از pandas
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {‘Name’:[‘Jai’, ‘Princi’, ‘Gaurav’, ‘Anuj’],
‘Age’:[27, 24, 22, 32]}
# Define a dictionary containing employee data
data2 = {‘Address’:[‘Allahabad’, ‘Kannuaj’, ‘Allahabad’, ‘Kannuaj’],
‘Qualification’:[‘MCA’, ‘Phd’, ‘Bcom’, ‘B.hons’]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1,index=[‘K0’, ‘K1’, ‘K2’, ‘K3’])
# Convert the dictionary into DataFrame
df1 = pd.DataFrame(data2, index=[‘K0’, ‘K2’, ‘K3’, ‘K4’])
display(df, df1)
# joining dataframe
res = df.join(df1)
res
خروجی :
Name Age
K0 Jai 27
K1 Princi 24
K2 Gaurav 22
K3 Anuj 32
Address Qualification
K0 Allahabad MCA
K2 Kannuaj Phd
K3 Allahabad Bcom
K4 Kannuaj B.hons
Name Age Address Qualification
K0 Jai 27 Allahabad MCA
K1 Princi 24 NaN NaN
K2 Gaurav 22 Kannuaj Phd
K3 Anuj 32 Allahabad Bcom

مصورسازی با Matplotlib
Matplotlib یک کتابخانه بصریسازی شگفتانگیز و آسان برای استفاده در پایتون است. این کتابخانه بر پایه آرایههای NumPy ساخته شده و به گونهای طراحی شده که با مجموعه SciPy کار کند. Matplotlib شامل چندین نوع نمودار مانند خطی، میلهای، پراکنده، هیستوگرام و غیره برای تحلیل داده است.
Pyplot
Pyplot یک ماژول از Matplotlib است که رابطی مشابه MATLAB فراهم میکند. Pyplot توابعی را فراهم میکند که با شکل تعامل دارند، به عنوان مثال، ایجاد یک شکل، تزئین نمودار با برچسبها و ایجاد یک ناحیه نمودار در یک شکل.
استفاده از Pyplot در Matplotlib
# Python program to show pyplot module
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.axis([0, 6, 0, 20])
plt.show()
خروجی:
این کد یک نمودار خطی را نمایش میدهد که محور x مقادیر [1, 2, 3, 4] و محور y مقادیر [1, 4, 9, 16] را نشان میدهد. تابع plt.axis محدودههای محورها را مشخص میکند و plt.show نمودار را نمایش میدهد.

نمودار میلهای
نمودار میلهای یا Bar Chart یک نمودار است که دستهبندیهای داده را با استفاده از میلههای مستطیلی نمایش میدهد که طول و ارتفاع آنها متناسب با مقادیری است که نمایندگی میکنند. نمودار میلهای میتواند به صورت افقی یا عمودی رسم شود. این نمودار مقایسه بین دستهبندیهای مجزا را توصیف میکند. میتوان آن را با استفاده از متد ()bar ایجاد کرد.
نمودار میلهای با استفاده از Matplotlib در پایتون
در این مثال از دیتاست iris استفاده میکنیم.
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv(“Iris.csv”)
# This will plot a simple bar chart
plt.bar(df[‘Species’], df[‘SepalLengthCm’])
# Title to the plot
plt.title(“Iris Dataset”)
# Adding the legends
plt.legend([“bar”])
plt.show()
خروجی:
این کد یک نمودار میلهای را نمایش میدهد که مقادیر SepalLengthCm را برای هر گونه (Species) از دیتاست Iris نشان میدهد. عنوان نمودار “Iris Dataset” است و یک legend با عنوان “bar” نیز اضافه شده است.

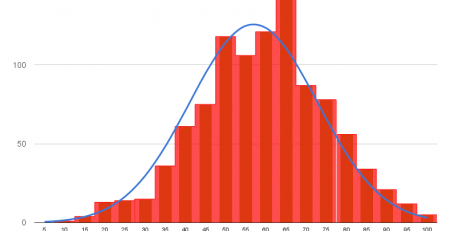
نمودار هیستوگرام
نمودار هیستوگرام به طور اساسی برای نمایش دادهها به صورت گروههایی برای تحلیل داده استفاده میشود. این نوع نمودار یک نوع نمودار میلهای است که در آن محور X بازههای بینی را نمایش میدهد در حالی که محور Y اطلاعات درباره فراوانی را ارائه میدهد. برای ایجاد یک هیستوگرام، ابتدا باید یک بن تعریف کنیم که بازهها را مشخص میکند، سپس مجموعهای از مقادیر را به این بازهها توزیع میکنیم و تعداد مقادیری را که در هر یک از بازهها قرار میگیرند، شمرده و ثبت میکنیم. بازهها به عنوان بازههای پیاپی و غیر همپوشانی متغیرها شناسایی میشوند. تابع () hist برای محاسبه و ایجاد هیستوگرام از x استفاده میشود.
هیستوگرام با استفاده از Matplotlib در پایتون
در این مثال از دیتاست iris استفاده میکنیم.
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv(“Iris.csv”)
plt.hist(df[“SepalLengthCm”])
# Title to the plot
plt.title(“Histogram”)
# Adding the legends
plt.legend([“SepalLengthCm”])
plt.show()
خروجی:
این کد یک نمودار هیستوگرام از متغیر SepalLengthCm در دیتاست Iris را نمایش میدهد. عنوان نمودار “Histogram” است و یک legend با عنوان “SepalLengthCm” نیز اضافه شده است.
نمودار پراکندگی
نمودارهای پراکندگی برای مشاهده رابطه بین متغیرها استفاده میشوند و از نقاط برای نمایش این رابطه استفاده میکنند. روش ()scatter در کتابخانه Matplotlib برای رسم نمودار پراکندگی استفاده میشود.
نمودار پراکندگی با استفاده از Matplotlib در پایتون
در این مثال از دیتاست iris استفاده میکنیم.
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv(“Iris.csv”)
plt.scatter(df[“Species”], df[“SepalLengthCm”])
# Title to the plot
plt.title(“Scatter Plot”)
# Adding the legends
plt.legend([“SepalLengthCm”])
plt.show()
خروجی:
این کد یک نمودار پراکندگی از متغیرهای Species و SepalLengthCm در دیتاست Iris را نمایش میدهد. عنوان نمودار “Scatter Plot” است و یک legend با عنوان “SepalLengthCm” نیز اضافه شده است.

نمودار جعبهای (Box Plot)
نمودار جعبهای یا همان box plot یک نمایش بسیار خوب است برای اندازهگیری توزیع دادهها است. این نمودار مشخص نمایانگر میانه، دادههای پرت و کوارتیلها است. درک توزیع دادهها یک عامل مهم است که منجر به ساخت بهترین مدلها میشود. اگر دادهها دارای پرتها باشند، نمودار جعبهای یک راهنمای توصیهشده است برای شناسایی آنها و اتخاذ اقدامات لازم.

Python Matplotlib Box Plot
در این مثال از دیتاست iris استفاده میکنیم.
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv(“Iris.csv”)
plt.boxplot(df[“SepalWidthCm”])
# Title to the plot
plt.title(“Box Plot”)
# Adding the legends
plt.legend([“SepalWidthCm”])
plt.show()
خروجی:
این کد یک نمودار جعبهای برای متغیر SepalWidthCm در دیتاست Iris رسم میکند. عنوان نمودار “Box Plot” است و یک legend با عنوان “SepalWidthCm” نیز اضافه شده است.

نمودار حرارتی همبستگی (Correlation Heatmap)
نمودار حرارتی همبستگی یک ابزار بسیار مفید برای تجسم ماتریس همبستگی دو بعدی بین دو بُعد گسسته در تحلیل داده است که با استفاده از سلولهای رنگی، اطلاعات را نمایش میدهد. این نمودار با استفاده از رنگها، اندازه پدیده را نشان میدهد. مقادیر بُعد اول به عنوان ردیفهای جدول ظاهر میشوند در حالی که بُعد دوم به عنوان ستونها. رنگ هر سلول به نسبت تعداد اندازهگیریهایی که با مقدار بُعدی همخوانی دارند، تغییر میکند.
نمودار حرارتی همبستگی (Python Matplotlib )
در این مثال از دیتاست iris استفاده میکنیم.
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv(“Iris.csv”)
plt.imshow(df.corr() , cmap = ‘autumn’ , interpolation = ‘nearest’ )
plt.title(“Heat Map”)
plt.show()
خروجی:
این کد یک نمودار حرارتی همبستگی برای دیتاست Iris رسم میکند. این نمودار با استفاده از رنگهای مختلف اطلاعات ماتریس همبستگی را نمایش میدهد. رنگبندی نمودار بهگونهای است که مقادیر مثبت و منفی همبستگی به روشنی قابل تمییز هستند.

این نمودار برای تحلیل دادهها بسیار مفید است زیرا الگوها را به طور آسان قابل خواندن میکند و تفاوتها و تغییرات در دادههای یکسان را برجسته میکند.
تحلیل اکتشافی دادهها (EDA)
تحلیل اکتشافی دادهها (EDA) یک تکنیک برای تحلیل داده ها با استفاده از روشهای بصری است. با استفاده از این تکنیک، میتوانیم اطلاعات دقیقی دربارهی خلاصه آماری دادهها بدست آوریم. همچنین قادر خواهیم بود که با مقادیر تکراری و موارد غیرعادی (outliers) برخورد کنیم و همچنین برخی روندها یا الگوهای موجود در دادهها را مشاهده کنیم.
دریافت اطلاعات دربارهی مجموعه دادهها
ما از پارامتر shape برای دریافت اندازه مجموعه دادهها استفاده خواهیم کرد.
df.shape
خروجی:
(150, 6)
میبینیم که این دیتافریم دارای ۶ ستون و ۱۵۰ ردیف است.
`حال بیایید ستونها و نوع دادههای آنها را نیز بررسی کنیم. برای این کار از متد () info استفاده خواهیم کرد.
اطلاعات دربارهی مجموعه دادهها
df.info()
خروجی:

میبینیم که تنها یک ستون دارای دادههای دستهبندیشده (categorical) است و بقیه ستونها دادههای عددی هستند و تمامی ورودیها فاقد مقادیر Null هستند.
بیایید یک خلاصه آماری سریع از مجموعه دادهها با استفاده از متد () describe بدست آوریم. تابع () describe محاسبات آماری پایهای مانند مقادیر نهایی، تعداد نقاط داده، انحراف معیار و غیره را بر روی مجموعه دادهها اعمال میکند. هر مقدار گمشده یا NaN بهصورت خودکار نادیده گرفته میشود. تابع () describe تصویری خوبی از توزیع دادهها ارائه میدهد.
توضیحات مربوط به مجموعه دادهها
df.describe()
خروجی:

میبینیم که تعداد مقادیر هر ستون همراه با میانگین، انحراف معیار، حداقل و حداکثر مقادیر نمایش داده میشوند.
بررسی مقادیر گمشده
ما بررسی خواهیم کرد که آیا دادههای ما دارای مقادیر گمشده هستند یا خیر. مقادیر گمشده زمانی اتفاق میافتند که هیچ اطلاعاتی برای یک یا چند آیتم یا برای کل یک واحد فراهم نشده باشد. برای این کار از متد () isnull استفاده خواهیم کرد.
کد پایتون برای بررسی مقادیر گمشده:
df.isnull().sum()
خروجی:

میبینیم که هیچ ستونی دارای مقادیر گمشده نیست.
بررسی دادههای تکراری
بیایید بررسی کنیم که آیا مجموعه دادههای ما حاوی مقادیر تکراری هست یا خیر. متد () drop_duplicates در کتابخانه پانداس به حذف دادههای تکراری از دیتافریم کمک میکند.
تابع پانداس برای حذف مقادیر تکراری:
data = df.drop_duplicates(subset=”Species”)
data
خروجی:

میبینیم که تنها سه گونه (species) منحصربهفرد وجود دارد. حالا بیایید بررسی کنیم که آیا مجموعه دادهها متعادل است یا خیر، یعنی آیا هر گونه دارای تعداد ردیفهای مساوی است یا خیر. برای این کار از تابع ()Series.value_counts استفاده خواهیم کرد. این تابع یک Series برمیگرداند که حاوی تعداد مقادیر یکتا است.
کد پایتون برای شمارش مقادیر در ستون:
df.value_counts(“Species”)
خروجی:

میبینیم که تمام گونهها (Species) دارای تعداد ردیفهای مساوی هستند، بنابراین نیازی به حذف هیچ ورودی نیست.
ارتباط بین متغیرها
ما رابطه بین طول کاسبرگ (Sepal Length) و عرض کاسبرگ (Sepal Width) و همچنین بین طول گلبرگ (Petal Length) و عرض گلبرگ (Petal Width) را بررسی خواهیم کرد.
مقایسه طول و عرض Petal
# وارد کردن پکیجها
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(x=’SepalLengthCm’, y=’SepalWidthCm’,
hue=’Species’, data=df)
# قرار دادن لِجِند (legend) خارج از نمودار
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
خروجی:

از نمودار بالا میتوان نتیجه گرفت که:
- گونه Setosa دارای طول کاسبرگ کوچکتر و عرض کاسبرگ بزرگتر است.
- گونه Versicolor در مقایسه با دو گونه دیگر، از نظر طول و عرض کاسبرگ در وسط قرار دارد.
- گونه Virginica دارای طول کاسبرگ بزرگتر و عرض کاسبرگ کوچکتر است.
مقایسه طول و عرض Petal
# وارد کردن پکیجها
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(x=’PetalLengthCm’, y=’PetalWidthCm’,
hue=’Species’, data=df)
# قرار دادن لِجِند (legend) خارج از نمودار
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
خروجی:

از تحلیل داده نمودار بالا میتوان نتیجه گرفت که:
- گونه Setosa دارای طول و عرض گلبرگهای کوچکتر است.
- گونه Versicolor در مقایسه با دو گونه دیگر از نظر طول و عرض گلبرگ در وسط قرار دارد.
- گونه Virginica دارای طول و عرض گلبرگهای بزرگتر است.
حال بیایید تمام روابط میان ستونها را با استفاده از pairplot ترسیم کنیم. این نمودار برای تحلیل چندمتغیره استفاده میشود.
کد پایتون برای pairplot:
# وارد کردن پکیجها
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df.drop([‘Id’], axis=1),
hue=’Species’, height=2)
خروجی:

از این تحلیل داده نمودار بالا میتوانیم انواع مختلفی از روابط را مشاهده کنیم، مانند اینکه گونه Setosa دارای کوچکترین عرض و طول petal ها و همچنین کوچکترین طول Sepal ولی بزرگترین عرض sepal است. اطلاعات مشابهی را میتوان درباره سایر گونهها نیز بدست آورد.
مدیریت همبستگی
متد () dataframe.corr در پانداس برای یافتن همبستگی جفتی (pairwise correlation) بین تمام ستونهای دیتافریم استفاده میشود. هر مقدار NA بهطور خودکار نادیده گرفته میشود و ستونهای غیرعددین در دیتافریم نادیده گرفته میشوند.
data.corr(method=’pearson’)
خروجی:

این خروجی نشان میدهد که چگونه ستونها بهطور جفتی با یکدیگر همبستهاند.
نمودار حرارتی (Heatmap)
نمودار حرارتی یک تکنیک بصریسازی دادهها است که برای تحلیل مجموعه دادهها بهصورت رنگها در دو بعد استفاده میشود. بهطور کلی، این نمودار همبستگی بین تمام متغیرهای عددی در مجموعه دادهها را نمایش میدهد. به عبارت سادهتر، میتوانیم همبستگیهای بدست آمده را با استفاده از نمودارهای حرارتی ترسیم کنیم.
کد پایتون برای نمودار حرارتی:
# وارد کردن پکیجها
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(df.corr(method=’pearson’).drop(
[‘Id’], axis=1).drop([‘Id’], axis=0),
annot=True)
plt.show()
خروجی:

از نمودار بالا میتوانیم نتیجهگیری کنیم که:
- عرض petal و طول petal همبستگی بالایی دارند.
- طول petal و عرض Sepal همبستگی خوبی دارند.
- عرض petal و طول Sepal همبستگی خوبی دارند.
مدیریت دادههای پرت
دادههای پرت (Outliers) اقلام/اشیائی هستند که بهطور قابل توجهی از سایر اشیاء (آنطور که بهطور معمول در نظر گرفته میشود) منحرف میشوند. این دادهها میتوانند ناشی از خطاهای اندازهگیری یا اجرایی باشند. تحلیل برای شناسایی دادههای پرت بهعنوان استخراج دادههای پرت (outlier mining) شناخته میشود. روشهای زیادی برای شناسایی دادههای پرت وجود دارد و فرآیند حذف آنها مشابه با حذف یک داده از دیتافریم پانداس است.
بیایید مجموعه دادههای Iris را در نظر بگیریم و نمودار جعبهای (boxplot) برای ستون SepalWidthCm ترسیم کنیم.
کد پایتون برای نمودار جعبهای:
# وارد کردن پکیجها
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# بارگذاری مجموعه داده
df = pd.read_csv(‘Iris.csv’)
sns.boxplot(x=’SepalWidthCm’, data=df)
خروجی:
در نمودار بالا، مقادیر بالای ۴ و پایین ۲ بهعنوان دادههای پرت عمل میکنند.
حذف دادههای پرت
برای حذف دادههای پرت، باید همان فرآیند حذف یک ورودی از مجموعه داده را با استفاده از موقعیت دقیق آن در مجموعه داده دنبال کنید. زیرا در تمام روشهای بالا برای شناسایی دادههای پرت، نتیجه نهایی لیستی از تمام دادههایی است که مطابق با تعریف دادههای پرت طبق روش استفاده شدهاند.
ما دادههای پرت را با استفاده از IQR شناسایی خواهیم کرد و سپس آنها را حذف خواهیم کرد. همچنین نمودار جعبهای (boxplot) را ترسیم خواهیم کرد تا ببینیم که آیا دادههای پرت حذف شدهاند یا خیر.
کد پایتون برای شناسایی و حذف دادههای پرت:
# وارد کردن پکیجها
import numpy as np
import pandas as pd
import seaborn as sns
# بارگذاری مجموعه داده
df = pd.read_csv(‘Iris.csv’)
# محاسبه IQR
Q1 = np.percentile(df[‘SepalWidthCm’], 25, interpolation=’midpoint’)
Q3 = np.percentile(df[‘SepalWidthCm’], 75, interpolation=’midpoint’)
IQR = Q3 – Q1
print(“Old Shape: “, df.shape)
# حد بالایی
upper = np.where(df[‘SepalWidthCm’] >= (Q3 + 1.5 * IQR))
# حد پایینی
lower = np.where(df[‘SepalWidthCm’] <= (Q1 – 1.5 * IQR))
# حذف دادههای پرت
df.drop(upper[0], inplace=True)
df.drop(lower[0], inplace=True)
print(“New Shape: “, df.shape)
sns.boxplot(x=’SepalWidthCm’, data=df)
خروجی:









دیدگاهتان را بنویسید